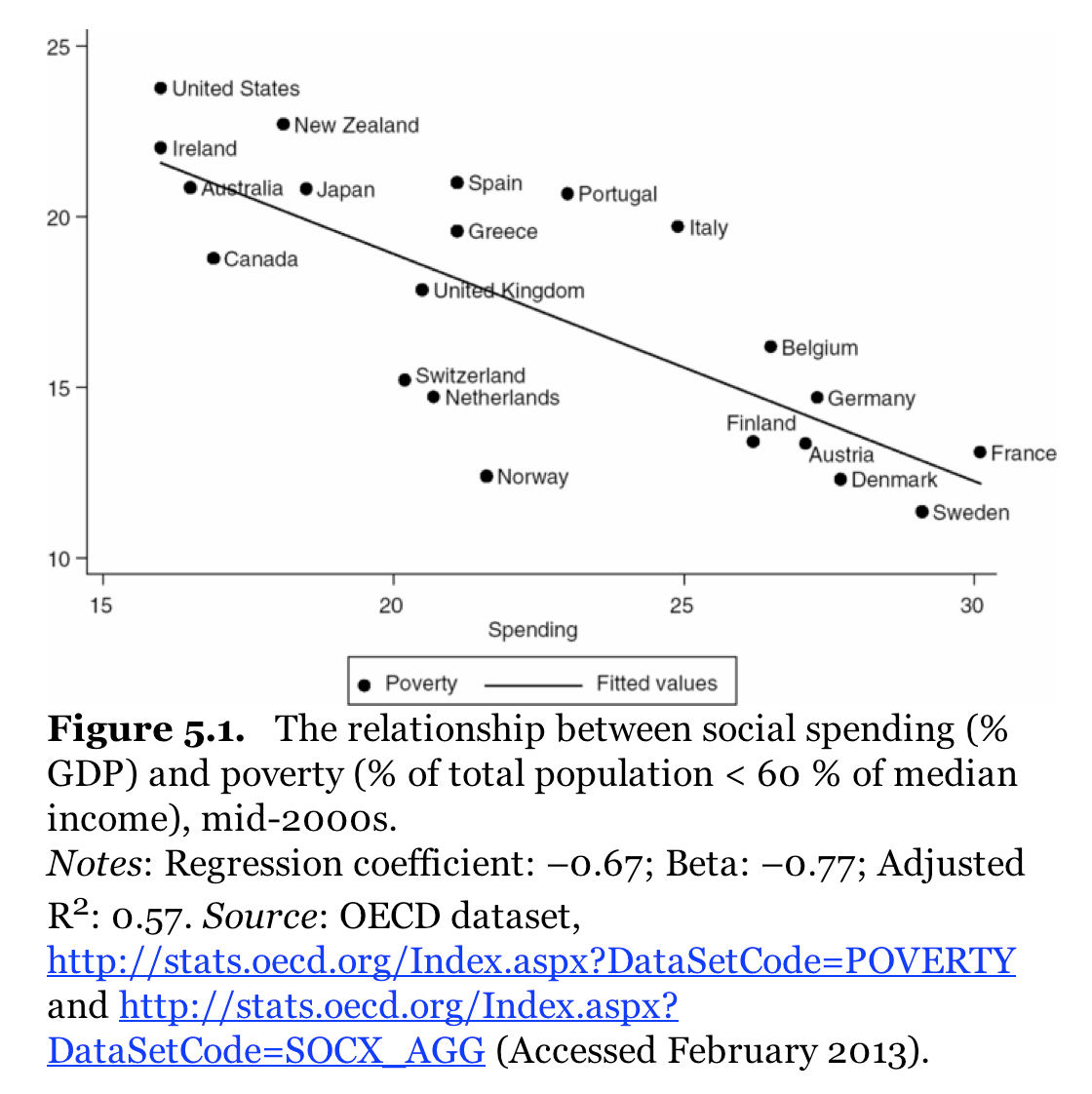
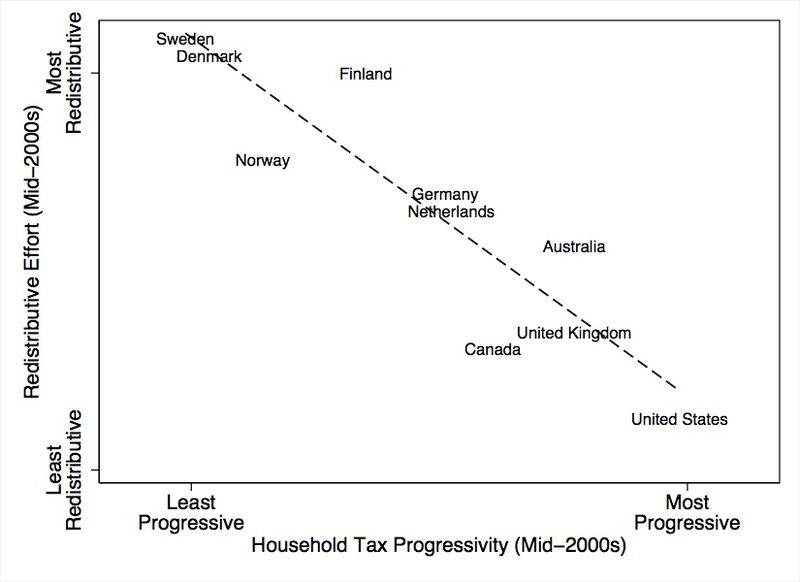
Trilemmas are always fun. Let’s do one. You may pick two, but no more than two, of the following:
- Liberalism
- Inequality
- Nonpathology
By “liberalism”, I mean a social order in which people are free to do as they please and live as they wish, in which everyone is formally enfranchised by a political process justified in terms of consent of the governed and equality of opportunity.
By “inequality”, I mean high dispersion of economic outcomes between individuals over full lifetimes. [1]
By “nonpathology”, I mean the absence of a sizable underclass within which institutions of social cohesion — families (nuclear and extended), civic and religious organizations — function poorly or at best patchily, in which conflict and violence are frequent and economic outcomes are poor. From the inside, a pathologized underclass perceives itself as simultaneously dysfunctional and victimized. From the outside, it is viewed culturally and/or morally deficient, and perhaps inferior genetically. Whatever its causes and whomever is to blame, pathology itself is a real phenomenon, not just a matter of false perception by dominant groups.
This trilemma is not a logical necessity. It is possible to imagine a liberal society that is very unequal, in which rich and poor alike make the best of their circumstances without clumping into culturally distinct groupings, in which shared procedural norms render the society politically stable despite profound quality of life differences between winners and losers. But I think empirically, no such thing has existed in the world, and that no such thing ever will given how humans actually behave.
It’s easy to find examples of societies with any two of liberalism, inequality, and nonpathology. You can have inequality in feudal or caste-based societies without pathology. The high castes may well perceive the low castes as inferior, and the low castes may regret their circumstances. But with the hierarchy sustained by overt force and a dominant ideology of staying in place, there is no need for pathology. Families and religious organizations in the lower castes might be strong, there may be little internal conflict, and no perception inside or outside the low status group that they are violating the norms of their society. There are simply overt and customary relations of domination and subordination. This was the situation of slaves in the American South prior to emancipation. They faced an unhappy and unjust circumstance, but a straightforward one. Whatever instabilities of family life or institutional deficiencies slaves endured were overtly forced upon them, and cannot reasonably be attributed to pathologies of the community, particularly given the experience of early Reconstruction. (More on this below.)
Contemporary Nordic countries do a fair job of combining liberalism and nonpathology. But that is only possible because they constitute unusually equal societies.
The United States today, of course, chooses liberalism and inequality, and so, I claim, it cannot survive without pathology. Why not? In a liberal society, humans segregate into groups based on economic circumstance. Economic losers become geographically and socially concentrated, and are not persuaded by the gloats of economic winners that outcomes were procedurally fair and should be quietly accepted. Unequal outcomes are persistent. As an empirical matter we know there is never very much rank-order economic mobility in unequal societies (nor should we expect or even wish that there would be). That should not be surprising, because the habits and skills and connections and resources that predict economic success will be disproportionately available within the self-segregated communities of winners. So, even if we stipulate for some hypothetical first generation that outcomes were procedurally fair, outcomes for future generations will be very strongly biased towards class continuity. Equality of opportunity cannot coexist with inequality of outcome unless the political community forcibly and illiberally integrates winners and losers (and perhaps not even then). But an absence of equality of opportunity is incompatible with the political basis of liberal society. If numerous losers are enfranchised and well-organized, they will seek and achieve redress (redistribution of social and economic goods and/or forced integration), or else the society must drop its pretense of liberalism and disenfranchise the losers, or at least concede the emptiness of any claim to legitimacy based on equality of opportunity.
Pathology permits a circumvention of this dilemma. It enables a reconciliation of equal opportunity with persistently skewed outcomes by claiming that persistent losers simply fail to seize the opportunities before them, as a result of their individual and communal deficiencies. Conflict within and between communities and the chaos of everyday life reduce the likelihood that even a very numerous pathologized underclass will effectively dispute the question politically. Conflict and “broken institutions” also serve as ipso facto explanations for sub-par outcomes. If the losers are sufficiently pathologized, it is possible to reconcile a liberal society with severe inequality. If they are not, the contradictions become difficult to paper over.
This may seem a very functional and teleological, some might even say conspiratorial, account of social pathology. It’s one thing to argue that it would be convenient, from an amoral social stability perspective, for the losers in an unequal society to behave in ways that appear from the perspective of winners to be pathological and that prevent losers from organizing to press a case the might upset the status quo. It’s another thing entirely to assert that so convenient a pathology would actually arise. After all, humans flourish when they belong to stable families, when they participate in civic and professional organizations, and when their communities are not riven by conflict and violence. Why would the combination of liberalism, inequality, and pathology be stable, when the underclass community could simply opt out of behaving pathologically?
Individual communities can opt out. Some do. But unless those communities embrace norms that eschew conventional socioeconomic pecking orders and/or political engagement with the larger polity (e.g. the Amish), it is entirely unstable for those nonpathological communities to remain underclass in a liberal polity. Suppose there were a community constituted of stable, traditional families. Its members were diligent, forward-looking, and hardworking, pursued education and responded to labor market incentives. And suppose this community was politically engaged, pressing its perspective and interests in government at all levels. In a liberal polity, it is just not supportable for such a community to remain a socioeconomic underclass. One of two things may happen: the community may press its case with the liberal establishment, identify barriers to the success of its members and work politically to overcome them, and eventually integrate into the affluent “middle class”. But if all underclass communities were to succeed in this way, there could be no underclass at all, there would be a massive decrease in inequality. Nonpathology requires equality. Alternatively, if severe inequality is going to continue, then there must remain some sizable contingent of people who are socioeconomic losers, who will as a matter of economic necessity become segregated into less-desirable neighborhoods, who will come to form new communities with social identities, which must be pathological for their poverty to be stable. Particular communities can opt out of pathology, but it is a fallacy of composition to suggest that that all communities can opt out of pathology in a polity that will remain both liberal and unequal.
If a society is, at a certain moment in time, deeply unequal, then pathology among the poor is required if status quo winners are to preserve their place, which, under sufficient dispersion of circumstance, can become a nearly existential concern for them. Consider the perspective of a liberal and well-intentioned member of the wealthy ruling elite of a poor, developing country. To “live as ordinary citizens live” would entail renouncing civilized life as she understands it. It would entail becoming a kind of barbarian. I don’t think the perspective of elites in less extreme but still unequal developed countries is all that different. Liberal elites need not and do not set about intentionally manufacturing pathology. They simply manage the arrangement of political and social institutions with a shared, tacit, and perfectly natural understanding that their own reduction to barbarism would count as a bad policy outcome and should be avoided. The set of policy arrangements consistent with this red line just happens to be disjoint from the set of arrangements under which there would not exist pathologized communities. Elite non-barabarism depends upon inequality, upon a highly skewed distribution of consumption and of the insurance embedded in financial claims, which must have justification. Elite non-barbarism may also depend very directly on the availability of cheap, low-skill labor. Liberal elites may be perfectly sincere in their handwringing at the state of the pathologized poor, laudable in their desire to “discover solutions”. Consider The Brookings Institution. But, under the constraints elites tacitly place on the solution space, the problems really are insoluble. The best a liberal policy apparatus can do is to resort to a kind of clientism in which the pathology of the underclass is handwrung and bemoaned, but nevertheless acknowledged as the cause and justification for continued disparity. Instruction (however futile) and a stigmatized means-tested “safety net” are sufficient to signal elites’ good intentions to themselves and absolve them of any need to revise their self-perceptions as civilized and liberal.
If pathology is necessary, it is also easy to get. Self-serving (mis)perceptions of pathology by elites of a poor community become self-fulfilling. Elites fearful of a “pathological” community will be more cautious about collaborating with their members economically, or hiring them. Privately, employers will subject members of the allegedly pathological community to more monitoring, impose more severe punishments based on less stringent evidence than they would upon members of communities that they trust. Publicly, concern over a community’s perceived pathology will translate to more intensive policing and laws or norms that de facto give authorities a freer hand among communities perceived to be pathological. Holding behavior constant, police attention creates crime, and a prevalence of high crime is ipso facto evidence of pathology. Of course, as pathology develops, behavior may not remain constant. Intensive monitoring (public and private) and the “positives” resulting from extra scrutiny justify ever more invasive monitoring and interference by authorities, which leads the monitored communities to very reasonably distrust formal authority. Cautiousness among employers contributes to economic precarity within the monitored community. Communities that distrust formal authority are like tiny failed statelets. Informal protection rackets arise to fill roles that formal authority no longer can. If no hegemon arises then these protection rackets become competitive and violent — “gangs!” — which constitute yet more clear evidence of pathology to outsiders. Economic precarity and employment disadvantage render informal and illicit economic activity disproportionately attractive, leading mechanically to more crime and sometimes quite directly to pathology, because some activities are illicit for a reason (e.g. heroin use). The mix of economic precarity and urban density loosens male attachment to families, a fact which has been observed not only recently and here but over centuries and everywhere, which increases poverty among women and children and engenders cross-generational pathology. Poverty itself becomes pathology within communities unable to pool risk beyond direct, also-poor acquaintances. Behavior that is perfectly rational for the atomized poor — acquiescence to unpleasant tradeoffs under conditions of crisis — appear pathological to affluent people who “would never make those choices” because they would never face those circumstances.
About a year ago, there was a rather extraordinary conversation between Ta-Nehisi Coates and Jonathan Chait. [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] At a certain point, Chait argues that the experience of white supremacy and brutality would naturally have left “a cultural residue” that might explain what some contemporary observers view as pathology. Coates responds:
What about the idea that white supremacy necessarily “bred a cultural residue that itself became an impediment to success”? Chait believes that it’s “bizarre” to think otherwise. I think it’s bizarre that he doesn’t bother to see if his argument is actually true. Oppression might well produce a culture of failure. It might also produce a warrior spirit and a deep commitment to attaining the very things which had been so often withheld from you. There is no need for theorizing. The answers are knowable.
There certainly is no era more oppressive for black people than their 250 years of enslavement in this country. Slavery encompassed not just forced labor, but a ban on black literacy, the vending of black children, the regular rape of black women, and the lack of legal standing for black marriage. Like Chait, 19th-century Northern white reformers coming South after the Civil War expected to find “a cultural residue that itself became an impediment to success.”
In his masterful history, Reconstruction, the historian Eric Foner recounts the experience of the progressives who came to the South as teachers in black schools. The reformers “had little previous contact with blacks” and their views were largely cribbed from Uncle Tom’s Cabin. They thus believed blacks to be culturally degraded and lacking in family instincts, prone to lie and steal, and generally opposed to self-reliance:
Few Northerners involved in black education could rise above the conviction that slavery had produced a “degraded” people, in dire need of instruction in frugality, temperance, honesty, and the dignity of labor … In classrooms, alphabet drills and multiplication tables alternated with exhortations to piety, cleanliness, and punctuality.
In short, white progressives coming South expected to find a black community suffering the effects of not just oppression but its “cultural residue.”
Here is what they actually found:
During the Civil War, John Eaton, who, like many whites, believed that slavery had destroyed the sense of family obligation, was astonished by the eagerness with which former slaves in contraband camps legalized their marriage bonds. The same pattern was repeated when the Freedmen’s Bureau and state governments made it possible to register and solemnize slave unions. Many families, in addition, adopted the children of deceased relatives and friends, rather than see them apprenticed to white masters or placed in Freedmen’s Bureau orphanages.
By 1870, a large majority of blacks lived in two-parent family households, a fact that can be gleaned from the manuscript census returns but also “quite incidentally” from the Congressional Ku Klux Klan hearings, which recorded countless instances of victims assaulted in their homes, “the husband and wife in bed, and … their little children beside them.”
This, I think, is a biting takedown of one theory of social pathology, that it arises as a sort of community-psychological reaction to trauma, an explanation that is simultaneously exculpatory and infantilizing. The “tangle of pathology” that Daniel Patrick Moynihan famously attributed to the black community did not refer to people newly freed from brutal chattel slavery in the late 1860s. It did not refer even to people in the near-contemporary Jim Crow South, people overtly subjugated by state power and threatened with cross-burnings and lynchings. No, the Moynihan report referred specifically to “urban ghettos”, mostly in the liberal North. The black community endured, in poverty and oppression but largely without “pathology”, precisely where it remained oppressed most overtly. For a brief period during Reconstruction, the contradictions between imported liberalism, non-negotiable inequality, and a not-all-at-pathological community of freedman flared uncomfortably bright. But before long (after, Coates points out, literal coups against the new liberal order), the South reverted to the balance it had always chosen, sacrificing liberalism for overt domination which permitted both inequality and a black community that lived “decently” according to prevailing norms but was kept unapologetically in its place.
Social pathology may be pathological for specific affected communities, but it is adaptive for the societies in which it arises. Like markets, pathology constitutes a functional solution to the problem of reconciling the necessity of social control with liberalism, which disavows many overt forms of coercion. A liberal society is a market society, because if identifiable authorities aren’t going to tell people what to do and force them, if necessary, to act, then a faceless, quasinatural market must do so. A liberal, unequal society “suffers from social pathology”, because the communities into which its losers collect must be pathological to remain so unequal. No claims are made here about causality. It is possible that some communities of people are, genetically or by virtue of some preexisting circumstance, prone to pathology, and pathology engenders inequality. It is possible that dispersion of economic outcomes is in some sense “prior”, and then absence of pathology becomes inconsistent with important social stability goals. Our trilemma is an equilibrium constraint, not a narrative. Whichever way you like to tell the story, a liberal society whose social arrangements would be badly upset by egalitarian outcomes must have pathology to sustain its underclass. The less consistent the requirements of civilized life among elites are with egalitarian outcomes, the greater the scale of pathology required to support the dispersion. That, fundamentally, is what all the handwringing in books like Coming Apart and Our Kids is about.
[1] We’ll be more directly concerned with “bottom inequality”, or “relative poverty” in OECD terms, rather than “top inequality” (the very outsized incomes of the top 0.1% or 0.001%).
The figure is from Comparative Welfare State Politics by Kerbergen and Vis.
Broadly speaking, top inequality is most relevant with respect to political and macroeconomic aspects of inequality (secular stagnation, plutocracy), while bottom inequality most directly touches social issues like family structure, labor market connectedness, social stratification, etc. Top and bottom inequality are obviously related, though the connection is not mechanical in a financial economy in which monetary claims can be created ex nihilio and the connection between monetary income and use or acquisition of real resources is loose.